预测与决策结合的范式
总结:不确定性的分类
不确定性分类
- 偶然不确定性(Aleatoric Uncertainty):由于数据本身的随机性和噪声导致的不确定性,是数据生成过程固有的。这类不确定性无法通过收集更多数据来消除。
- 认知不确定性(Epistemic Uncertainty):由于模型知识不足或参数估计不准确导致的不确定性。这类不确定性可以通过收集更多数据、改进模型等方式来减少。
公式说明(符号定义)
本文档中使用的主要符号定义如下:
| 符号 | 含义 | 说明 |
|---|---|---|
| $\theta$ | 模型参数 | 需要通过训练优化的参数 |
| $\hat{y}$ | 预测值 | 预测模型输出的预测结果 |
| $y$ | 真实值/观测值 | 实际观测到的值或标签 |
| $M(\cdot)$ | 决策函数 | 将预测值映射到最优决策的函数 |
| $L(\cdot)$ | 损失函数 | 量化决策质量的函数,通常与决策效果相关 |
| $f(z; y)$ | 目标函数 | 优化问题中的目标函数 |
| $z^*$ | 最优决策 | 在给定参数下的最优决策 |
| $\hat{z}^*$ | 预测最优决策 | 基于预测值得到的最优决策 |
| $\varepsilon$ | 扰动强度 | 近似方法中添加的噪声大小 |
| $\tau$ | 温度参数 | 光滑函数中的温度参数 |
一、摘要:数据驱动方法的核心概念
数据驱动的决策方法已成为现代优化和机器学习的核心范式。本部分介绍了端到端学习(End-to-End Learning)在预测与决策结合中的应用。
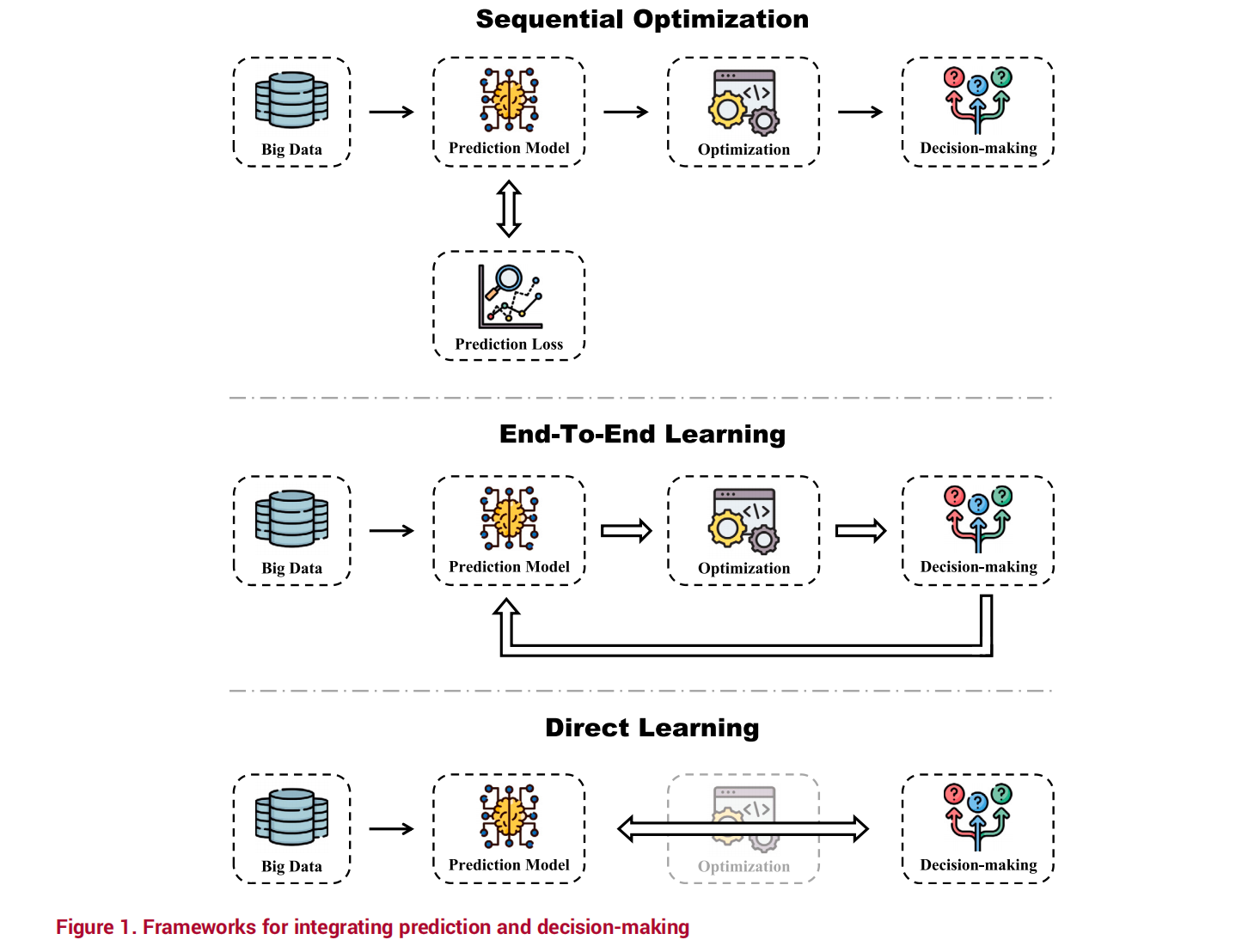
展示端到端学习(End-to-End Learning)在预测与决策结合中的应用,以及数据驱动方法的核心概念。
端到端学习的优势
| 优势项 | 说明 |
|---|---|
| 联合优化 | 预测和决策目标联合优化,避免两阶段方法的次优解 |
| 信息保留 | 保留预测模型中的不确定性信息,用于决策 |
| 梯度传播 | 决策层的梯度可以直接反向传播到预测层 |
| 适应性强 | 模型可以自动学习预测中最关键的特征用于决策 |
| 效率提升 | 减少了预测-决策间的信息损失,提高整体效率 |
| 性能改善 | 实证研究表明端到端学习通常优于传统两阶段方法 |
端到端学习的劣势
| 劣势项 | 说明 |
|---|---|
| 模型复杂性 | 联合优化增加了模型的复杂性和训练难度 |
| 可解释性降低 | 端到端模型的决策过程相对黑盒,可解释性较差 |
| 计算成本 | 需要在决策层进行复杂的优化计算,增加计算开销 |
| 数据需求 | 需要更多的标注数据来训练联合模型 |
| 泛化性能 | 在分布外数据上的泛化性能可能不如两阶段方法 |
| 调试困难 | 当模型性能不佳时,难以定位问题出在预测还是决策层 |
二、三种范式:预测与决策的不同组合方式
在预测与决策的结合中,存在三种主要的范式,分别代表了不同的设计哲学和应用场景。
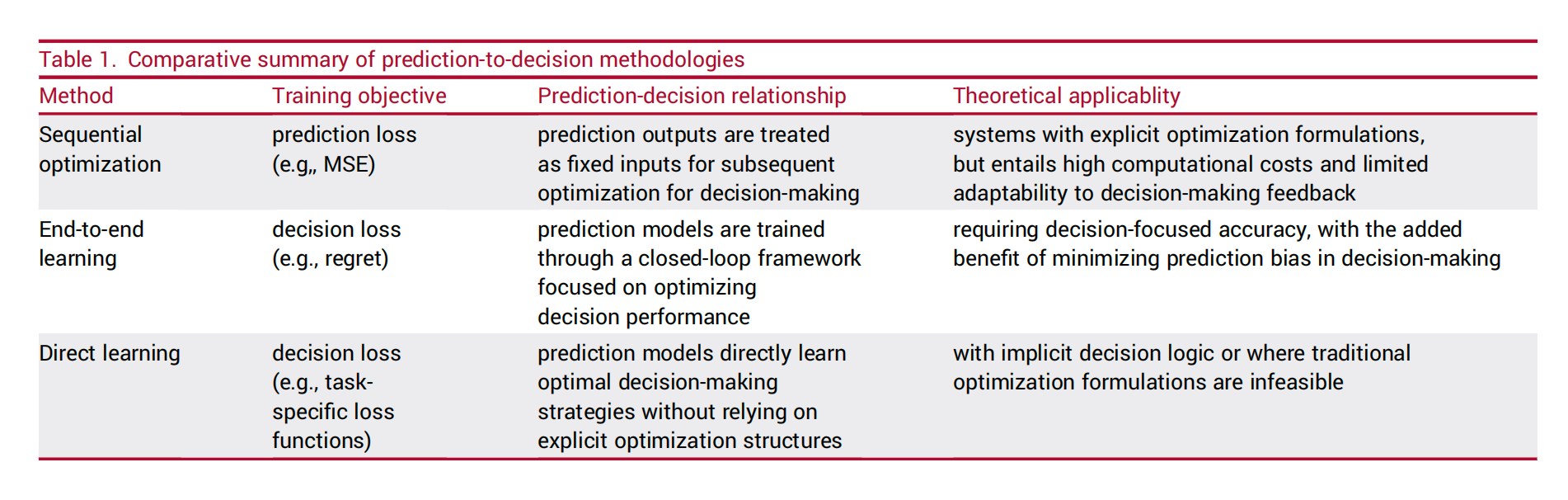
展示预测与决策结合的三种主要范式:预测驱动决策、决策驱动预测和预测-决策联合优化。
三种范式对比
| 范式 | 特点 | 应用场景 |
|---|---|---|
| SO(Separate Optimization) | 预测和决策分开优化,两阶段方法 | 预测和决策目标差异大,可独立优化的场景 |
| E2E(End-to-End) | 预测和决策联合优化,决策驱动学习 | 预测和决策紧密耦合,需要联合优化的场景 |
| DL(Direct Learning) | 直接学习决策函数,跳过显式预测 | 只关心最终决策结果,不需要中间预测的场景 |
1. SO 预测与决策的错配
问题描述
在传统的两阶段方法(Separate Optimization)中,预测模型和决策模型是分开训练的,这导致了以下问题:
错配的根源
- 目标函数不一致:预测模型优化的是预测精度(如MSE、MAE),而决策模型优化的是决策质量(如收益、成本)
- 信息丢失:预测模型输出通常是点估计,丢失了不确定性信息,而决策模型可能需要这些信息
- 梯度断裂:决策层的错误无法反向传播到预测层,预测模型无法根据决策反馈改进
- 次优解:预测精度最优不等于决策质量最优,可能导致整体性能不佳
影响
- 系统整体性能低于理论上界
- 对预测误差敏感,小的预测偏差可能导致决策大幅偏离最优
- 难以利用决策反馈来改进预测
2. E2E 决策驱动学习
核心概念
端到端学习(End-to-End Learning)通过将决策层集成到神经网络中,使得预测和决策能够联合优化。决策层的梯度可以直接反向传播到预测层,从而实现"决策驱动学习"。
数学模型
说明:这个公式表示端到端学习的目标函数。通过最小化决策损失 $L$ 的期望来优化模型参数 $\theta$,其中 $M(\cdot)$ 是决策函数,将预测值映射到最优决策。
其中:
- $\theta$ 是模型参数
- $\hat{y}$ 是预测值
- $y$ 是真实值
- $M(\cdot)$ 是决策函数
- $L(\cdot)$ 是损失函数(通常与决策质量相关)
反向传播
说明:链式法则展示了梯度如何从决策层反向传播到预测层。决策函数的梯度 $\frac{\partial M(\hat{y})}{\partial \hat{y}}$ 是关键,它决定了预测误差对决策的影响。
优势
- 预测模型学习最关键的特征用于决策
- 决策质量直接优化,避免了SO方法中的错配
- 充分利用决策反馈来改进预测
- 理论上可以达到更优的整体性能
梯度计算挑战
主要挑战在于计算中间项 $\frac{\partial\mathcal{M}(\hat{\mathbf{y}})}{\partial\hat{\mathbf{y}}}$(即最优决策 $\mathcal{M}(\hat{\mathbf{y}})$ 对预测参数 $\hat{\mathbf{y}}$ 的梯度)。对于具有解析解的优化任务,这些梯度可以使用显式表达式直接导出[27]。在无约束优化场景中,泰勒展开技术可以有效简化梯度计算[28]。然而,在一般的约束优化问题中,决策结果由底层的优化结构隐式决定,这一过程变得非常复杂,需要专门的方法来精确评估梯度。
3. DL 直接学习
核心思想
直接学习(Direct Learning)跳过显式的预测步骤,直接学习从原始特征到决策的映射函数。这种方法适用于只关心最终决策结果,不需要中间预测结果的场景。
适用场景
- 决策结果是唯一的关注点
- 中间预测结果不需要被人类理解或使用
- 计算资源有限,无法承担额外的预测模块
与E2E的区别
- E2E:保留显式预测,预测和决策联合优化
- DL:完全跳过预测,直接优化决策
三、E2E三种方法对比
一句话总结
在端到端学习框架下,实现决策驱动学习的主要有三种方法:
- 隐式微分:通过隐函数定理求解KKT条件,获得决策对预测的梯度
- 代理损失:设计替代损失函数,使其优化结果与原决策问题一致
- 近似方法:用光滑的近似函数替代原决策函数,便于梯度计算
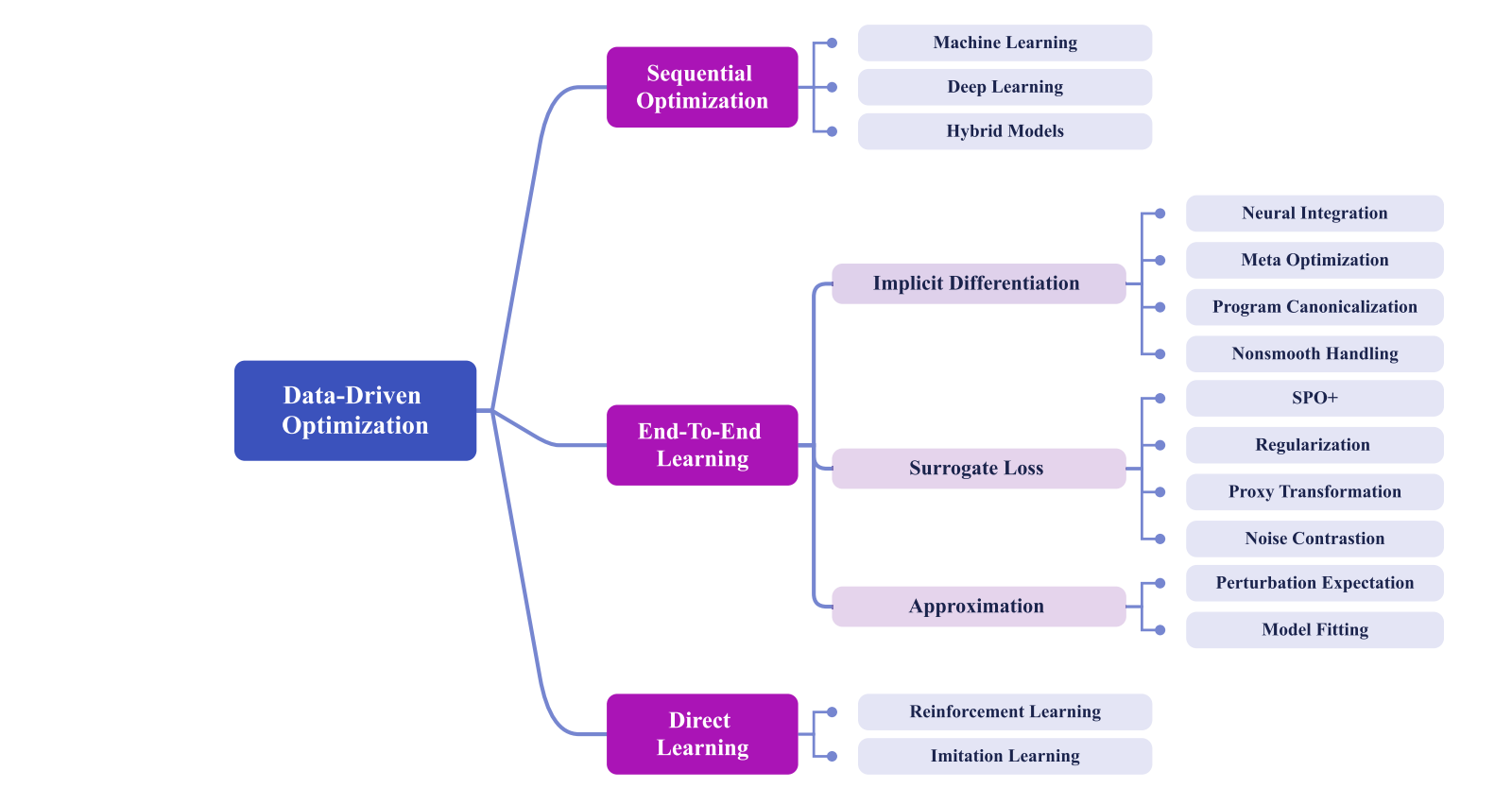
隐式微分、代理损失和近似方法三种决策驱动学习方法的对比示意图。
三种方法对比表
| 方法 | 核心原理 | 优点 | 缺点 | 适用场景 | 计算复杂度 | 可解释性 |
|---|---|---|---|---|---|---|
| 隐式微分 | 隐函数定理求梯度 | 精确、无近似 | 计算复杂、需求解器 | 凸优化问题 | 高 | 高 |
| 代理损失 | 设计替代损失函数 | 简单易实现、计算快 | 可能不精确、需要设计 | 特定问题类型 | 低 | 中 |
| 近似方法 | 光滑函数近似 | 通用性强、易实现 | 近似误差、参数调优 | 通用场景 | 中 | 中 |
1. 隐式微分(Implicit Differentiation)
核心思想
隐式微分利用隐函数定理(Implicit Function Theorem)来计算决策对预测的梯度。对于一个优化问题,最优解满足KKT条件。通过对KKT条件求导,可以得到最优解对参数的梯度。
数学原理
对于优化问题:
$$z^* = \arg\min_z f(z; y)$$其中 $y$ 是预测值。最优性条件为:
$$\nabla_z f(z^*; y) = 0$$对 $y$ 求导:
$$\frac{\partial z^*}{\partial y} = -[\nabla_{zz}^2 f(z^*; y)]^{-1} \nabla_{yz}^2 f(z^*; y)$$说明:隐式微分方法通过隐函数定理计算最优决策 $z^*$ 关于预测值 $y$ 的梯度。这避免了显式求解决策问题,但需要计算 Hessian 矩阵。
$$\frac{\partial z^*}{\partial y} = -[\nabla_{zz}^2 f(z^*; y)]^{-1} \nabla_{yz}^2 f(z^*; y)$$隐式微分的梯度计算
对于复合函数 $L(z^*(y))$,链式法则给出:
$$\frac{\partial L}{\partial y} = \frac{\partial L}{\partial z^*} \cdot \frac{\partial z^*}{\partial y}$$适合场景
| 场景 | 描述 |
|---|---|
| 凸优化问题 | 目标函数和约束都是凸的,保证最优解唯一 |
| 可微分问题 | 目标函数二阶可微,Hessian矩阵可逆 |
| 参数化线性规划 | 如库存管理、资源分配等 |
优点
优点
- 精确计算梯度,无近似误差
- 理论基础坚实,数学上严格
- 对小规模问题效率高
- 可以处理任意可微的目标函数
缺点
缺点
- 需要计算和反演Hessian矩阵,计算复杂度高
- 对于大规模问题不可行
- Hessian矩阵可能不可逆或病态
- 需要调用外部优化求解器
- 对于非凸问题可能失效
典型应用
- 库存管理:预测需求,通过隐式微分优化库存决策
- 投资组合优化:预测收益,通过隐式微分优化资产配置
- 电力调度:预测负荷,通过隐式微分优化发电计划
- 运输路由:预测需求,通过隐式微分优化配送方案
2. 代理损失(Surrogate Loss,SPO+)
核心思想
代理损失方法(特别是SPO+)的核心思想是设计一个替代的损失函数,使得最小化这个替代损失函数等价于或近似等价于最小化原始的决策成本。这样可以避免直接处理离散或非光滑的决策问题。
SPO+ 损失函数
SPO+ 的损失函数定义为:
$$L_{SPO+} = -(2\hat{y} - y)^T M(2\hat{y} - y) + (2\hat{y} - y)^T M(y)$$其中:
- $\hat{y}$ 是预测值
- $y$ 是真实值
- $M(\cdot)$ 是决策函数
- $2\hat{y} - y$ 是预测误差的倍数
梯度计算
适合场景
| 场景 | 描述 |
|---|---|
| 线性决策问题 | 决策函数是参数的线性函数 |
| 组合优化问题 | 如旅行商问题、背包问题等 |
| 整数规划问题 | 决策变量是整数 |
关键限制
主要限制
- 线性假设:SPO+ 要求决策函数是参数的线性函数,对于非线性决策问题不适用
- 完全信息假设:假设真实参数 $y$ 已知,但实际中 $y$ 也是预测的
- 凸性要求:要求决策问题是凸的
- 参数规模:对于高维参数空间,计算效率下降
典型应用
- 库存管理:SPO+ 最初应用于库存优化问题
- 价格优化:预测需求曲线,优化定价策略
- 资源分配:在约束条件下优化资源分配
- 运输物流:预测需求,优化运输方案
优点
优点
- 实现简单,易于集成到神经网络中
- 计算效率高,梯度计算快速
- 对于线性决策问题理论上最优
- 已有成熟的理论分析
- 在多个实际应用中验证有效
缺点
缺点
- 仅限于线性决策问题
- 对非线性或组合优化问题的扩展困难
- 在某些情况下可能导致预测偏差
- 需要显式计算决策函数 $M(\cdot)$
- 对于大规模问题可能不够高效
3. 近似方法(Approximation Methods)
核心思想
在具有多面体可行域和线性目标的优化中,梯度信息的有效性也存在问题,为了改善梯度的光滑性和可微性,学者们引入了使用噪声的概念近似方法。通过对预测值加噪声,把“一个确定的最优解”变成“多个解的加权平均”,从而绕过不可导的断点,让预测模型能够学会如何为决策服务。
数学原理
对于离散决策问题,用光滑函数近似:
$$\tilde{z}^* = g_{\tau}(\nabla_z f(z; y))$$其中 $g_{\tau}(\cdot)$ 是温度参数为 $\tau$ 的光滑函数(如Softmax)。
当 $\tau \to 0$ 时,$\tilde{z}^* \to z^*$。
扰动方法
另一种近似方法是通过添加随机扰动:
$$z_{\text{perturb}}^* = \mathbb{E}_{\varepsilon}[M(\tilde{y} + \varepsilon Z)]$$其中 $\varepsilon$ 是扰动强度,$Z$ 是随机矩阵。
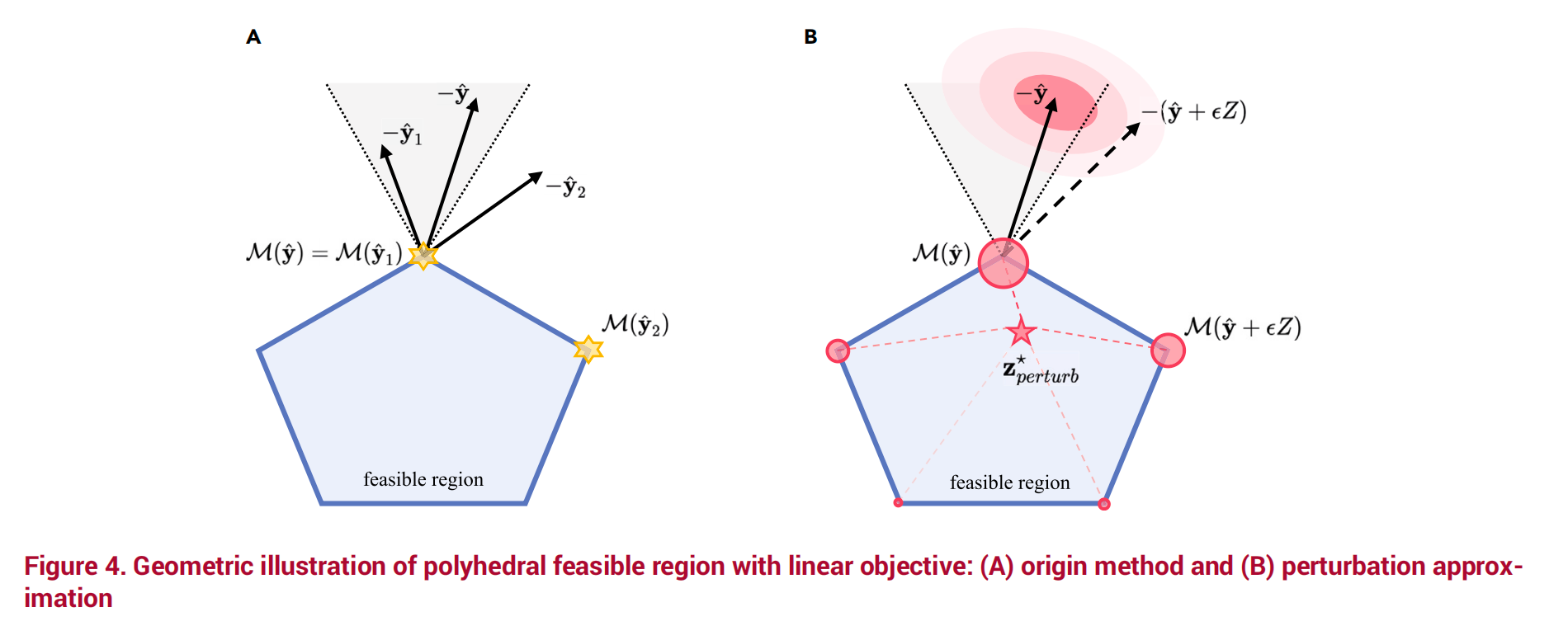
展示了在非可微决策函数下的多种近似方法:直接优化、梯度估计、参数化决策函数和随机扰动等技术的对比。
适合场景
| 场景 | 描述 |
|---|---|
| 非凸优化问题 | 决策问题是非凸的 |
| 离散决策问题 | 决策变量是离散的 |
| 组合优化问题 | 涉及排列、组合等离散结构 |
| 通用场景 | 对大多数决策问题都适用 |
典型应用
- 神经组合优化:使用注意力机制近似旅行商问题(TSP)的解
- 排序问题:使用Softmax近似排序操作
- 图神经网络:在图结构学习中使用Gumbel-Softmax
- 强化学习:使用温度缩放的Softmax作为策略
优点
优点
- 通用性强,适用于各种类型的决策问题
- 实现相对简单,易于与深度学习框架集成
- 计算效率高,梯度计算快速
- 可以处理离散和组合优化问题
- 灵活性高,可根据问题特点调整近似方式
缺点
缺点
- 近似引入误差,可能影响决策质量
- 需要调优近似参数(如温度 $\tau$)
- 理论分析相对复杂,收敛性保证困难
- 对于某些问题,近似效果不理想
- 可能需要多次实验来找到最优的近似方式
四、常见问题
如何处理不确定性和模型误差?
现象
在实际应用中,预测模型往往存在系统偏差或过度自信,导致决策偏离最优。特别是在以下情况下问题更突出:
- 训练数据分布与实际数据分布不一致
- 模型容量不足,无法捕捉复杂的数据关系
- 特征工程不充分,遗漏了关键特征
- 超参数设置不合理,导致过拟合或欠拟合
- 数据中存在异常值或标注错误
Root Cause
不确定性和模型误差的根本原因包括:
- 数据质量问题:训练数据不足、噪声大、标注不准确
- 模型设计缺陷:模型结构不适合问题,超参数设置不当
- 分布偏移:训练数据与测试数据来自不同分布
- 特征空间不完整:缺少关键信息,无法完全解释目标变量
- 优化困难:优化过程陷入局部最优,未收敛到全局最优
解决方案
针对不确定性和模型误差,有以下几种处理方法:
1. 不确定性量化
- 贝叶斯深度学习:使用Bayesian Neural Networks或MC Dropout来估计预测的不确定性
- 集成方法:训练多个模型,通过预测的方差来衡量不确定性
- 分位数回归:预测置信区间而不仅仅是点估计
2. 鲁棒决策
- 鲁棒优化:在最坏情况下优化决策,对不确定性进行防御
- 随机规划:考虑不确定性的概率分布,进行期望值优化
- 自适应决策:根据实时反馈动态调整决策
3. 模型改进
- 数据增强:增加训练数据量,改进数据质量
- 特征工程:发现和创造更好的特征
- 模型选择:尝试不同的模型架构和算法
- 超参数优化:系统地搜索最优的超参数组合
4. 在线学习和反馈
- 持续学习:随着新数据到达,不断更新模型
- 反馈循环:收集决策反馈,用于改进预测模型
- 多臂赌博机:在探索和利用之间平衡,逐步学习最优决策
脚注与参考
处理不确定性的关键要点:
- 不确定性是不可避免的,关键是如何有效地量化和利用它
- 鲁棒性和适应性是实际应用中的重要考虑
- 端到端学习可以自动学习如何在不确定性下做出最优决策
- 多种方法的组合通常优于单一方法
- 持续的反馈和改进是长期成功的关键
总结
关键要点
- 预测与决策的结合是现代优化和机器学习的重要方向
- 端到端学习通过联合优化预测和决策,可以获得更好的性能
- 三种主要方法(隐式微分、代理损失、近似方法)各有优缺点,应根据具体问题选择
- 不确定性处理是实际应用中的关键,需要量化、量化和适应
- 持续改进是获得最优性能的必要条件