LLM 在运筹学中的应用:方法、应用与挑战
LLM + OR 的三大核心范式深度解析
📑 页面目录
大语言模型(LLM)在运筹学(OR)中的应用可以系统地划分为三大核心范式:自动建模(Automatic Modeling)、辅助优化求解(LLM-Assisted Optimization)和 LLM 主导的直接求解(LLM-Dominated Optimization Solving)。以下是对这三大范式、当前学术界/业界的聚焦点以及基准测试(Benchmarks)的总结。
一、LLM + OR 的三大核心范式深度解析
1. 自动建模范式(Automatic Modeling)
这是将自然语言问题转化为计算机可识别的数学模型的”桥梁”阶段。
解决的问题
- 降低运筹学建模门槛,解决传统依赖专家建模耗时耗力的问题。
- 解决长文本描述中关键约束遗漏和语义歧义的问题。
基本逻辑与流程
核心在于翻译。LLM 接收自然语言描述的优化问题,将其转化为形式化的数学模型(如变量、目标函数、约束条件)或可执行代码(如 Python/Gurobi 代码)。流程通常包含五个步骤闭环:理解(解析目标与约束)→ 提取(识别决策变量等元素)→ 结构化(生成标准模型)→ 转译(生成求解器代码)→ 评估与反馈(运行代码并修正错误)。
主要子路径
- 基于提示词(Prompting):通过多阶段或多智能体提示,引导 LLM 生成模型组件。
- 提示词与微调协同(Prompt-Fine-tuning Synergy):结合 SFT 和提示工程,解决单一提示的不稳定性。
- 外部知识引导(Knowledge-Augmented):引入 RAG 注入领域特定知识,处理复杂约束。
关键发表
- OptiMUS
- Chain-of-Experts
- LLaMoCo
- IndustryOR
- DROC 等
评估
具有工业应用价值,是实现”人人可用的运筹学”的关键,正从简单 MILP 向复杂图结构和非标准约束扩展。
2. 辅助优化求解范式(LLM-Assisted Optimization)
LLM 不直接给出最终解,而是充当算法设计师或搜索算子,辅助传统算法(如进化算法、强化学习)进行求解。
解决的问题
- 自动化算法设计,解决传统启发式设计依赖人工经验的问题。
- 突破局部最优,发现人类未曾想到的新算法结构。
基本逻辑与流程
LLM 利用其代码生成能力和推理能力,生成启发式算法、搜索算子或奖励函数,与传统优化算法形成”感知-推理-反馈”闭环。
主要子路径
- 启发式结构进化(Heuristic Evolution)
- 多目标协同(Multi-Objective)
- 跨范式融合(Cross-Paradigm)
关键发表
- FunSearch
- EoH
- LMEA
- AEL
- ReEvo
- Hercules
- MEoH
- HSEvo
- PoH
- CALM
- EALG
- HeurAgenix
- GraphThought 等
评估
学术界最热门方向,结合了 LLM 的创造力与传统算法的严谨性,是通向”自动算法设计”的必经之路。
3. LLM 主导的直接求解范式(LLM-Dominated Optimization Solving)
LLM 被视为一个独立的”求解器”,直接输出最终解。
解决的问题
- 针对难以显式建模的”黑盒”问题提供快速、通用的解决方案。
- 适用于小规模或快速原型验证场景。
基本逻辑与流程
- 零建模:无需构建数学模型或编写算法代码,用户输入问题描述,LLM 直接输出解决方案。
- 通常利用 CoT 或 Meta-Prompt 技术,通过多轮对话引导 LLM 自我修正。
主要子路径
- 单模态:仅依赖文本交互。
- 多模态结构感知:结合视觉输入增强空间感知能力。
关键发表
- OPRO
- MLLM-V 等
特点与局限
- 特点:通用性强,无需训练,交互灵活。
- 局限:容易产生幻觉,难以处理大规模问题或复杂约束,性能波动大。
二、学术界与业界当前的聚焦点
系统化与闭环
研究重心已从单点任务验证转向构建完整的智能优化系统,强调”生成-验证-修复”闭环。
核心聚焦范式
- 辅助优化(特别是启发式进化)是学术界的焦点:FunSearch 等工作证明了其发现新知识的潜力。
- 自动建模是工业界的应用热点:通过微调和 RAG 技术,该方向正变得越来越实用。
- 直接求解范式相对边缘化:目前更多用于简单问题或作为启发式初值生成器。
三、当前的基准测试总结
1. 针对"自动建模"能力的 Benchmark
- NL4OPT:早期基础基准。
- IndustryOR:工业覆盖面最广,含 16 个行业 1556 个问题。
- ComplexOR:高难度验证基准。
- MAMO、OptiBench / ReSocratic、EquivaMap 等。
2. 针对"求解与推理"能力的 Benchmark
- NLGraph、GraphArena、CO-Bench、FrontierCO、HeuriGym、ALE-Bench 等。
3. 针对"可解释性"的 Benchmark
- EOR:第一个工业级可解释性优化数据集。
更详细论文及应用见附录
1. 关键范式一:自动建模
1.1 基于提示词的路径
| 论文/机构 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| OptiMUS (Cornell) | 2024 | 模块化建模代理系统,引入连接图机制 | 长文本关键信息丢失,复杂问题分解 | 提升大规模问题建模准确率 |
| Chain-of-Experts (NUS/Huawei) | ICLR 2024 | 多角色 Agent 协作,前向构建+后向反思 | 减少逻辑幻觉,提高模型正确性 | 提升代码可执行率 |
| OptLLM (Alibaba) | 2024 | 三阶段交互式对话,主动消除歧义 | 用户需求表述不清 | 提升意图理解准确性 |
| NL2OR | 2025 | 生成 DSL + JSON Schema 验证 | 语法错误和 API 调用错误 | 保证语法正确性 |
| Autoformulator | 2024 | MCTS + 分层分解 | 寻找最佳数学表述 | 验证系统性探索能力 |
| MA-GTS | 2025 | 多智能体框架,重构图拓扑结构 | 图结构提取困难 | 实现自然语言到图结构的映射 |
| OR-LLM-Agent | 2025 | 推理驱动的闭环,自我修复 | 代码无法运行或逻辑错误 | 实现端到端自动化求解 |
1.2 提示词与微调协同
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| AI Copilot | 2023 | 拆解为 9 个子模块 + SFT | Token 限制,生成完整性 | 确保代码完整性和可执行性 |
| Li et al. | 2023 | 三阶段微调框架 | 变量遗漏和约束误判 | 减少变量遗漏和误判 |
| LLaMoCo | 2024 | Code-to-Code 指令微调 + 对比学习 | Prompt 不稳定性 | 泛化能力强 |
| Evo-Step-Instruct | - | 进化数据生成 + 逐步验证 | 高质量数据稀缺 | 提升稳定性 |
| LLMOPT | 2024 | 五元组建模结构 + MI-SFT + KTO | 输出格式不统一 | 提升标准化和稳定性 |
| OptMATH (PKU) | 2025 | 三元组数据集 + LoRA + 反馈机制 | 语义鸿沟 | 提升数学表达与代码实现对齐 |
| STR-CMP (SJTU) | 2025 | 结构引导生成 + DPO 迭代 | 对隐含结构感知弱 | 生成更符合求解器规范的代码 |
1.3 外部知识引导机制
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| DROC | ICLR 2025 | 语义检索提取约束知识 | 缺乏领域业务规则 | 处理复杂现实约束 VRP |
| a knowledge-guided automated MILP modeling framework (HUST) | 2025 | 领域知识库指导变量和约束生成 | 敏感数据无法上传,专业性不足 | 强稳定性和生成能力 |
2. 关键范式二:辅助优化求解
2.1 启发式结构进化与策略优化
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| LMEA | IEEE CEC 2024 | Zero-shot 算子,温度自适应 | 算子设计依赖人工 | 减少设计复杂度 |
| AEL (SUSTech) | CoRR 2024 | 算法自我进化,LLM4AD 平台 | 自动发现新算法逻辑 | 优于人工设计方案 |
| ARS (CUHK, Huawei) | 2025 | 约束感知启发式构造 | VRP 变体规则设计耗时 | 端到端优化 |
| FunSearch (Google DeepMind) | Nature 2024 | 程序搜索+评估器,分布式架构 | LLM 幻觉 | 发现超越人类的新算法 |
| QUBE | 2024 | 不确定性指标指导父代选择 | 陷入局部最优 | 提升质量和稳定性 |
| ReEvo | NeurIPS 2024 | 双层反思(短期+长期) | 难以从数值反馈学习 | 效率显著提升 |
| AutoSAT | 2024 | 模块替换,评估候选函数 | 求解器组件难以调优 | 自动化提升性能 |
| CRISPE / ZSO | Cluster Computing 2024 | 结构化 Prompt 框架 | Prompt 质量影响大 | 强收敛稳定性 |
| HeurAgenix | 2025 | 多智能体协作(生成/进化/评估/选择) | 单一 Agent 兼顾困难 | 自适应启发式演化 |
| SeEvo | 2024 | 种群自进化,个体+集体反思 | 动态车间调度适应性 | 优于传统静态规则 |
| HSEvo | AAAI 2025 | 和声搜索 + 角色扮演 Prompt | 维持多样性 | 增强适应性并维持多样性 |
| GraphThought | 2025 | 思维生成,推理路径+模板合成 | 图结构识别 | 推进图优化结构识别 |
| AutoHD | 2025 | “探索+修改”策略 | 复杂规划推理效率 | 提升求解质量和效率 |
| PAIR | 2025 | 人类偏好选择,结构化 Prompt | 选择机制缺乏语义指导 | 赋予选择和调节能力 |
| CEoH | 2025 | 上下文驱动,结构化 Prompt | 适应性差 | 生成更具针对性的启发式 |
| Hercules | KDD 2025 | 性能预测 + 置信度控制 | 评估成本高 | 平衡生成与评估 |
| RedAHD | 2025 | 语言缩减 + 并行进化 | 原问题过于复杂 | 扩展启发式发现边界 |
| MoH | 2025 | 双层元优化(外层生成优化器) | 优化器结构固定 | 强泛化能力 |
| EALG | 2025 | 对抗协同进化(问题 vs 求解器) | 鲁棒性不足 | 提升难度和策略适应性 |
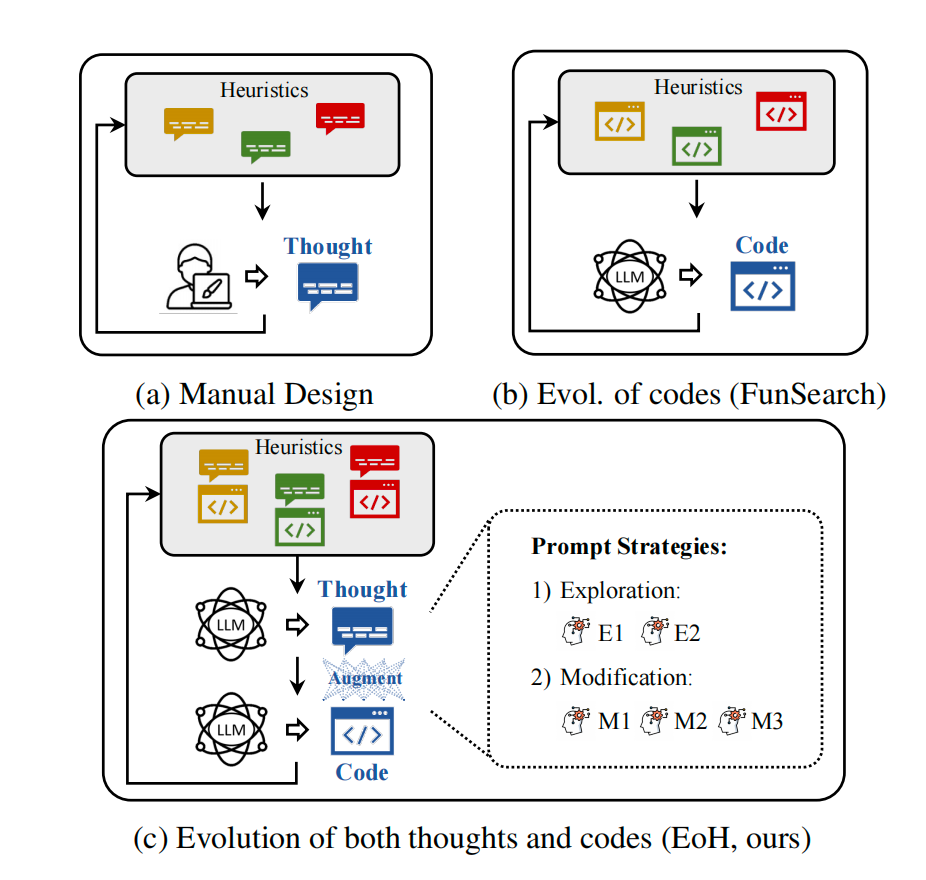
图:EoH(Evolution of Heuristics)方法框架
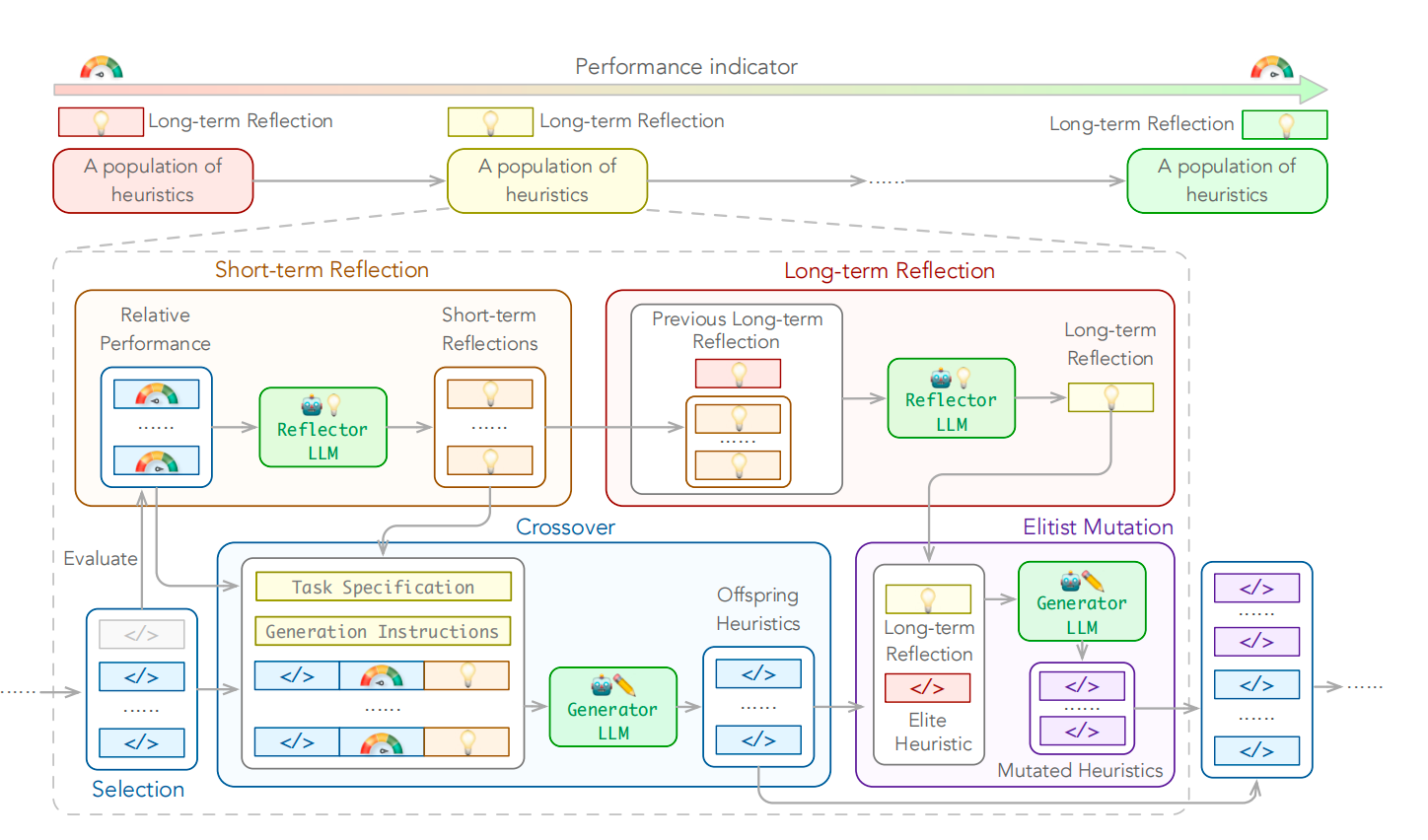
图:ReEvo(Reflective Evolution)方法框架
2.2 多目标优化协作
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| MOEA/D-LLM | EMCO 2025 | 子代生成 + 线性算子 | 计算成本高 | 降低成本,保持泛化 |
| CCMO | ICIC 2024 | LLM 作为搜索算子嵌入 CCMO | 收敛速度慢 | 加速收敛,提升质量 |
| Low-cost Adaptive | 2024 | 按需调用 LLM | 资源受限 | 有限资源下提升质量 |
| Huang et al. | IEEE TEVC 2025 | 生成可执行变异算子代码 | 固定算子缺乏适应性 | 增强适应性和结构灵活性 |
| MEoH | AAAI 2025 | 非支配启发式集合 | 多目标策略单一 | 自动进化非支配启发式 |
| REMOH | 2025 | 聚类反思 + NSGA-II | 多样性与鲁棒性 | 提升多样性和鲁棒性 |
| MLHH | ICLR 2025 | 统一超启发式框架 | 缺乏统一演化框架 | 系统级多目标策略优化 |
| IlmPC-NSGA-II | IEEE CEC 2024 | 嵌入 NSGA-II,生成完整子代种群 | 金融应用 | 验证收敛性和多样性 |
2.3 跨范式融合
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| Sartori et al. | 2025 | LNS/BRKGA 融合,年龄偏差+熵正则化 | 缺乏结构感知 | 提升结构感知能力 |
| Ye et al. | - | 双层 LNS,内层生成策略,外层进化 Prompt | 搜索效率 | 平衡效率与收敛 |
| Wang et al. | IEEE SMC 2024 | 三阶段 Prompt + 温度控制 | 局部最优 | 增强跳出局部最优能力 |
| AutoDH | IEEE ICSP 2024 | RL 策略选择启发式函数池 | 策略动态调整 | 实现子路径优化和反馈驱动 |
| Evo-Tune | 2025 | 程序采样 + DPO | 生成质量 | 偏向更高质量结构 |
| CALM (CUHK) | 2025 | GRPO + 崩塌-重启 | 稳定性 | 提升鲁棒性和稳定性 |
| Jiang et al. | 2024 | 神经符号系统,语义编码+RL | 语义与结构统一 | 统一语义与结构约束 |
| LLM+NCO solver | ICLR 2025 | 生成注意力偏置,集成到 POMO/LEHD | 跨规模泛化 | 轻量级微调下跨规模泛化 |
| S2RCQL | ICIC 2025 | 空间 Prompt + Q-learning | 空间推理弱 | 降低学习难度,提升稳定性 |
| MCTS-AHD (NUS) | 2025 | 双重调用机制(生成启发式+语义描述) | 语义一致性 | 增强语义一致性和可解释性 |
| PoH | ICML 2025 | MCTS 主导,状态-动作-奖励闭环 | 缺乏全局规划 | 改善全局搜索 |
3. 关键范式三:LLM 主导的直接求解
3.1 单模态生成优化
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| OPRO (Google DeepMind) | 2024 | Meta-Prompt 迭代,无梯度/无算子 | 黑盒优化 | 证明 LLM 自主探索解空间潜力 |
| Guo et al. | 2023 | CoT + 历史记忆 | 推理深度 | 从单次生成到交互收敛 |
| Dellma (USC) | 2024 | 效用建模,状态预测+偏好排序 | 不确定环境决策 | 提升决策鲁棒性 |
| Self-debugging (USC) | 2024 | NL 转 Python → 执行 → 调试 → 验证 | 解的可行性 | Zero-shot 优化 VRP |
| Self-Guiding Exploration | NeurIPS 2024 | 递归子任务优化 | 解的范围与多样性 | 扩展解空间 |
| Gcoder (HKU) | 2024 | SFT + RLF + RAG | NL 到图代码映射 | 跨任务泛化 |
| ACCORD | 2025 | 约束感知解码,强制满足约束 | 复杂约束满足 | 统一求解 NP-hard 问题 |
3.2 多模态结构感知
| 论文/作者 | 年份 | 核心逻辑 | 解决的问题 | 效果 |
| MLLM-V | IEEE MCII 2025 | 图文 Prompt 融合,模拟人类视觉认知 | 空间感知缺失 | 视觉信息显著提升 VRP 解质量 |
| Elhenawy et al. | 2024 | 纯视觉驱动,双智能体架构 | 坐标依赖 | 处理复杂几何结构优化 |
4. 综合基准测试
4.1 自动建模基准测试
| 基准名称 | 发表信息 | 核心逻辑 | 解决的问题与效果 |
| ComplexOR | ICLR 2024 | 测试复杂长文本建模鲁棒性 | 评估复杂问题建模 |
| IndustryOR | Operations Research 2025 | 16 个行业 1556 个问题 | 接近人类专家水平 |
| OptiBench (ReSocratic) | 2024 | 反向翻译增强数据 | 提升 LLaMA 在 MILP 上的表现 |
| Extended OptiBench | ICLR 2025 | 80+ 领域,816 个问题 | 强化跨任务评估 |
| EquivaMap | arXiv 2025 | 结构等价性检测 | 判断语义等价性 |
| TEXT2ZINC | arXiv 2025 | MiniZinc 标准化,110 个问题 | 证明 CoT 优于直接 Prompt |
| CP-Bench | arXiv 2025 | 101 个问题,241 种约束类型 | Python 框架更适合建模 |
4.2 优化求解基准测试
| 基准名称 | 发表信息 | 核心逻辑 | 解决的问题与效果 |
| NLGraph | NeurIPS 2023 | 8 类图推理任务 | 评估图问题解决能力 |
| PPNL | ICLR 2024 | 网格世界路径规划 | 评估空间导航推理 |
| AsyncHow | PMLR 2024 | 多步异步任务,1600 个实例 | 评估任务依赖处理 |
| GraphArena | ICLR 2025 | 三阶段评估,幻觉检测 | 诊断推理过程 |
| ORQA | AAAI 2025 | 20 个领域,1513 个选择题 | 评估运筹学知识 |
| EOR | ICLR 2025 | 可解释性,30 类问题 | 填补解释性评估空白 |
| CO-Bench | arXiv 2025 | 36 类现实问题,全流程评估 | 评估算法设计端到端能力 |
| FrontierCO | arXiv 2025 | 8 项组合优化任务评估 | 比较 LLM 与神经/启发式方法 |
| HeuriGym | ICLR 2026 | 生成-反馈-细化闭环 | 评估启发式设计成功率和质量 |
| ALE-Bench | arXiv 2025 | 基于 AtCoder 的长视界优化 | 评估多轮迭代和长期规划 |
| OPT-BENCH | arXiv 2025 | 20 个超参优化 + 10 个 NP-hard | 评估大规模搜索空间表现 |